WHAT IS KUBERNETES
- Kubernetes is a container orchestration.
- OpenSource system for automating deployment, scaling, and management of containerized apps.
- Started by Google in 2015. Now it is a part of the Cloud Native Computing Foundation project.
- Each container is encapsulated in PODs. Multiple PODs are deployed using ReplicaSet.
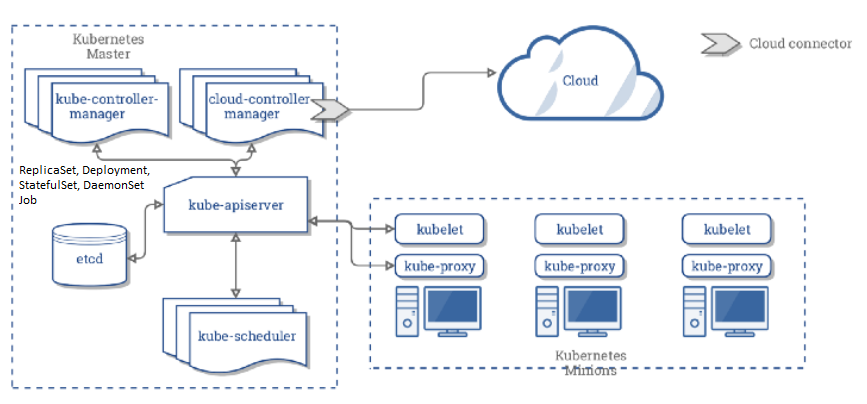
HOW DOES KUBERNETES WORKS
KUBERNETES FEATURES
- Service discovery and load balancing (exposing pod with name/ip and can't balancing traffic).
- Storage orchestration (mount external storage service).
- Automated rollouts and rollbacks (modifying deployment with yaml file).
- Automatic bin packing (customizing resource).
- Self-healing (auto stop/start/restart/changing container to became ready to serve).
- Secret and configuration management (storing sensitive information such as password, token, etc).
KUBERNETES ARCHITECTURE
Master nodes (control-plane) controls and coordinates all the nodes and continuously maintaining the desired state throughout your cluster. Master process :
kube-apiserver the single point of management for the entire cluster. The API server implements a RESTful interface for communication with tools and libraries. The kubectl command directly interacts with the API server. Kube-apiserver jobs are :
- Authenticate user
- Validate request
- Retrieve data
- Update ETCD
- Scheduler
- Kubelet
kube-controller-manager which performs cluster-level functions, such as replicating components, keeping track of worker nodes, handling node failures, and so on.
kube-scheduler which schedules your apps (assigns a worker node to each deployable component of your application).
ETCD is a reliable distributed data store that persistently stores the cluster configuration. Kubernetes uses etcd to store configuration data that can be accessed by each of the nodes in the cluster. This can be used for service discovery and can help components configure or reconfigure themselves according to up-to-date information.
What is key-value store? store information in a key-value format in database, for example:
- cannot have duplicate keys.
- not used as replacements
- used to store small and retrieve small chunks of data such as configuration key value name Darin position IT Architecture Engineer
ETCD in kubernetes, store information regarding cluster such as Nodes, PODs, Configs, Secrets, Accounts, Roles, Binding, Others. If you setup kubernetes from scratch, you need to deploy and configure etcd server manually. If you setup cluster using kubeadm, then kubeadm deploys the etcd server as a pod in the kube-system namespace.
you can explore etcd database using etcdctl: kubectl exec etcd-master -n kube-system etcdctl get / --prefix -keys-only
Worker nodes. worker nodes are basically worker machines (VMs, physical, bare metal servers, etc) in a cluster running your workloads. The nodes are controlled by Kubernetes master and are continuously monitored to maintain the desired state of the application. Worker process :
- Container runtime (Docker).
- Kubelet (agent that communicates with the k8s master and manage containers on its node). If you deploy kubernetes cluster using kubeadm, it doesnt automatically install kubelet (thats the difference with the others component), you must always manually install kubelet on worker node.
- Kube-proxy (network proxy that reflects k8s networking services on each node. Its responsible for implementing a form of virtual IP for Services).
Addons.
- DNS.
- Web UI (Dashboard).
- Container Resource Monitoring.
- Cluster Level Logging.
KUBERNETES OBJECTS
- Pod is a collection of containers with shared storage and network, and a specification on how to run them. Each pod is allocated its own IP address. Creating a pod using yaml file configuration
kubectl create -f pod-definition.yaml</br>
always contain 4 top level/properties (required) in the configuration file:
apiVersion:
kind:
metadata:
spec:apiVersion: v1
kind: Pod [the types of object]
metadata: [data about of the object. like name/object/label ]
name: myapp-pod
labels:
app: myapp
type: front-end
spec: [dictionary]
containers: [list/array]
- name: nginx-container
image: nginx
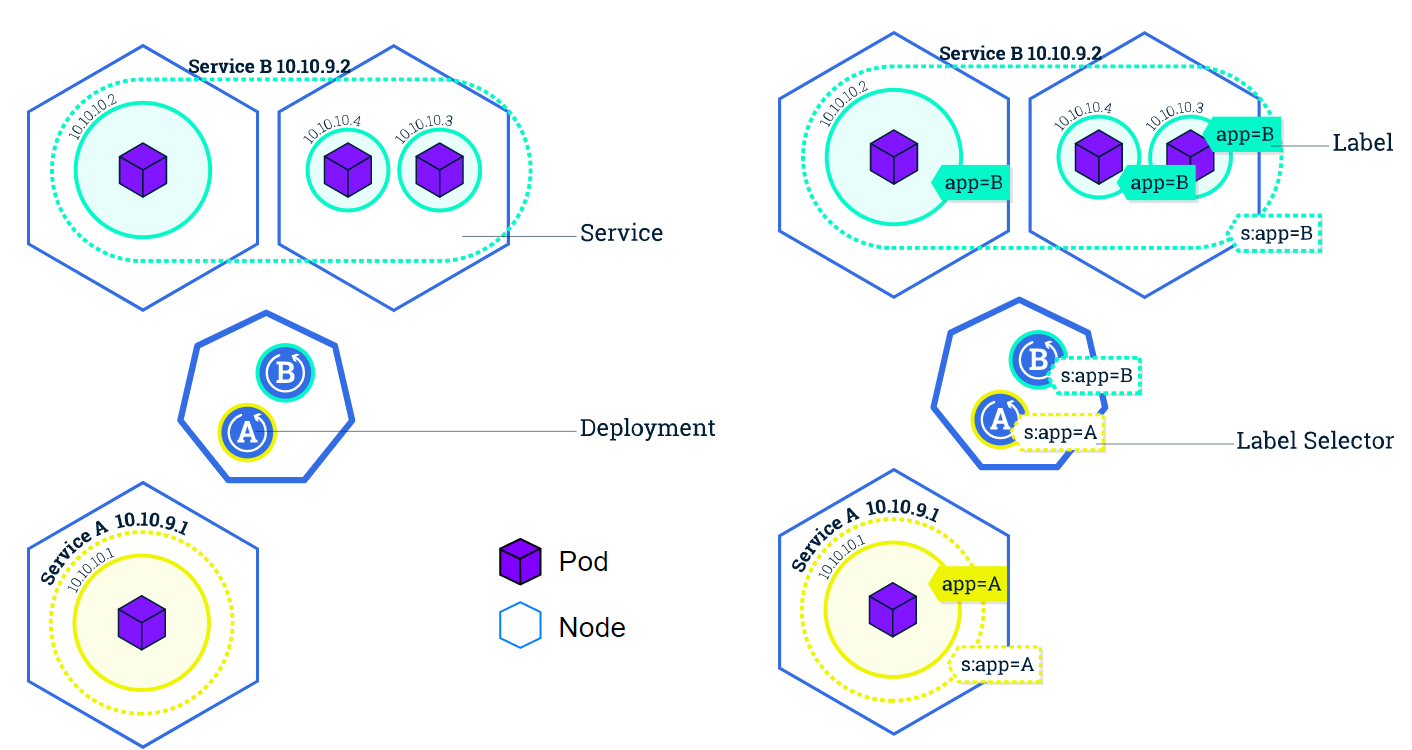
- name: backend-container- Service is used to define a logical set of Pods and related policies used to access them. Exposing to external world mechanism.
- Volume is essentially a directory accessible to all containers running in a Pod.
- Namespace are virtual clusters backed by the physical cluster. Three namespace default is default (namespace contains the objects which belong to any other namespace), kube-system (namespace contains the objects created by the Kubernetes system), and kube-public (special namespace, which is readable by all users and used for special purposes, like bootstrapping a cluster). Pods, deployments, and services are inside Namespace. In namespaces, you can do resource limit, dns resolution (a pod can connect to other pod using hostname in the same namespace).
apiVersion: v1
kind: Namespace
metadata:
name: devapiVersion: v1
kind: Pod
metadata:
name:myapp-pod
namespace: other-namespace
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-controller
image: nginxTo limit resources in Namespaces, using ResourceQuota.
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: dev
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: 5Gi
limits.cpu: "10"
limits.memory: 10GiKUBERNETES CONTROLLERS
- ReplicaSet ensures that a specified number of Pod replicas are running at any given time. When you edit existing ReplicaSet on your cluster such as image-name, it doesnt automatically updating on every pods. You need to delete Pod and let the replicaset replace it.
ReplicationController and ReplicaSet
ReplicationController = older technology that is being replaced by ReplicaSet.
#ReplicationController
apiVersion: v1
kind: ReplicationController
metadata:
name: myapp-rc
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-pod
spec:
containers:
- name: nginx-controller
image: nginx
replicas: 3#ReplicaSet
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-pod
spec:
containers:
- name: nginx-controller
image: nginx
replicas: 3
selector: #Necessary in ReplicaSet
matchLabels:
type: front-end- Deployment is used to change the current state to the desired state. Provides the capability to upgrade the underlying pods seamlessly using rolling updates, undo changes, and pause changes as required. Deployment automatically create a ReplicaSet.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deployment
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-pod
spec:
containers:
- name: nginx-controller
image: nginx
replicas: 3
selector:
matchLabels:
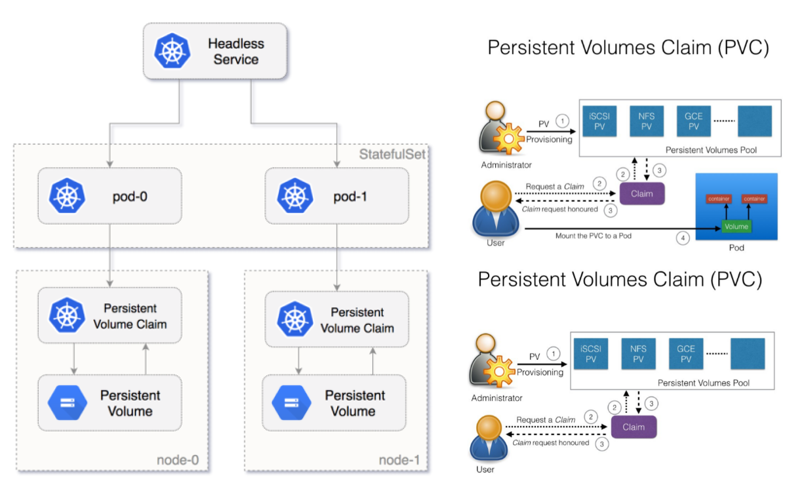
type: front-end- StatefulSet is used to ensure control over the deployment ordering and access to volumes, etc.
- DaemonSet is used to ensure control over the deployment ordering and access to volumes, etc.
- Job is used to perform some task and exit after successfully completing their work or after a given period of time.
KUBERNETES NETWORKING
Kubernetes using three different types of networks :
- Infrastructure Network is the network your physical (or virtual) machines are connected to. Normally your production network, or a part of it.
- Service Network is the (completely) virtual (rather fictional) network, which is used to assign IP addresses to Kubernetes Services, which you will be creating. There is three types of kubernetes service which is NodePort (30000-32767), ClusterIP, and LoadBalancer.
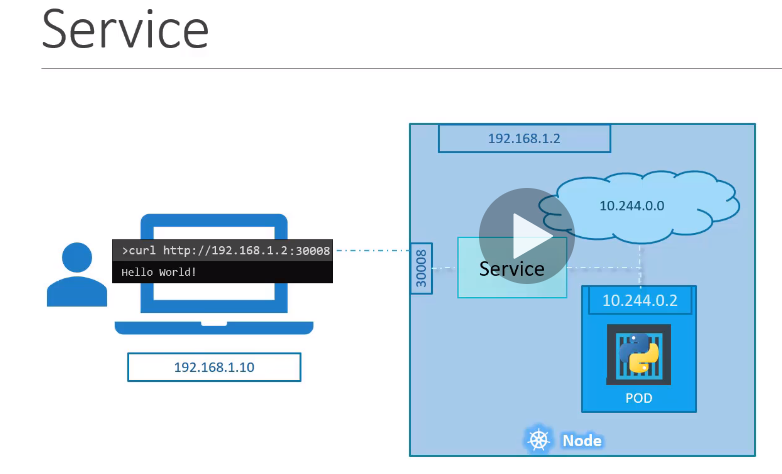
- Pod Network is the network which is used by the pods.
Networking between components in kubernetes :
- Container to container communication inside a pod (share the network namespaces).
- Pod to pod communication accros nodes (using routable pods and nodes like GCE or SDN like flannel/calico/weave).
- Communication between the external world and pods (exposing services to the external world with kube-proxy).
ACCESSING KUBERNETES CLUSTER
- CLI using kubectl.
- GUI using kubernetes-dashboard.
- APIs.
KUBERNETES SERVICE TYPE
- ClusterIP Service (default) : exposes the service on an internal IP in the cluster. This type makes the Service only reachable from within the cluster.
- NodePort Service : exposes the service on the same port of each selected Node in the cluster using NAT. Makes a service accessible from outside the cluster using NodeIP:NodePort.
- LoadBalancer Service : creates an external load balancer in the current cloud (if supported) and assigns a fixed, external IP to the service.
KUBERNETES OBJECT MODEL
apiVersion: apps/v1 #apiVersion, API endpoint on API server which we want to connect to
kind: Deployment #kind, object type
metadata: #metadata, basic information of object
name: nginx-deployment
spec: #spec, desire state of deployment
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort:80KUBERNETES VOLUME MANAGEMENT
KUBERNETES (KUBECTL) USEFULLL COMMAND
Help : kubectl -h
Syntax : kubectl [command] [TYPE] [NAME] [flags]
-- command : Specifies the operation (create, get, describe, delete)
-- type : Specifies the resource type.
-- name : Specifies the name of the resource.
-- flags : Specifies optional flags.
kubectl api-resources #Print the supported API resources on the server.
kubectl get apiservices #Print the supported API services on the server.
kubectl get all|endpoints|nodes|pods|deployments|services|secrets|replicaset|resourcequota -o wide|json|yaml
kubectl get all|endpoints|nodes|pods|deployments|services|secrets|replicaset|resourcequota --all-namespaces
kubectl cluster-info
kubectl config view
kubectl apply -f FILENAME [flags]
kubectl apply -f kubernetes-dashboard.yaml
kubectl create -f FILENAME [flags]
kubectl create namespaces app01
kubectl create secret ...
kubectl create -f app01.yaml
kubectl create 0f app01.yaml --namespace=name
kubectl delete
kubectl describe
kubectl edit
kubectl edit deployment apache02
kubectl exec POD
kubectl exec -it apache02 /bin/bash
kubectl expose [type] [name] [--port=port] [--protocol=TCP|UDP] [--target-port=number-or-name] [--name=name] [--external-ip=external-ip-of-service] [--type=type]
kubectl expose deployment apache02 --port=80 --protocol=TCP --type=NodePort --external-ip=103.x.x.x
kubectl expose pod redis --port=6379 --name redis-service --dry-run=client -o yaml
kubectl logs POD
kubectl logs apache02
kubectl run NAME --image=image [--port=port] [--replicas=replicas] [--labels]
kubectl run apache02 --image=httpd --port=80 --replicas=3 --labels="name=apache02"
#generate manifestasi yaml file, use --dry-run to not creating.
#deployment doesnt have replicas, so you can scale it later.
kubectl create deployment --image=nginx nginx --dry-run -o yaml
kubectl create deployment --image=nginx nginx --dry-run -o yaml > nginx-deployment.yaml
kubectl create service clusterip redis --tcp=6379:6379 --dry-run=client -o yaml
kubectl replace -f [file].yaml
kubectl scale -replicas=x -f [file].yaml
#changing default namespace
kubectl config set-context $(kubectl config current context) --namespace=x
Reference :
https://kubernetes.io/docs/reference/kubectl/overview/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#
https://kubernetes.io/docs/reference/kubectl/cheatsheet/KUBERNETES SECRETS
A Secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Such information might otherwise be put in a Pod specification or in an image; putting it in a Secret object allows for more control over how it is used, and reduces the risk of accidental exposure.
Users can create secrets, and the system also creates some secrets.
To use a secret, a pod needs to reference the secret. A secret can be used with a pod in two ways: as files in a volume mounted on one or more of its containers, or used by kubelet when pulling images for the pod.
https://kubernetes.io/docs/concepts/configuration/secret/
GLOSARIUM
- Ingress
- Flannel
KUBERNETES BASIC MODULS
- Create a k8s cluster
- Deploy an app
- Explore your app
- Explore your app publicly
- Scale up your app
- Update your app
Reference : https://medium.com/sannycloud/apa-itu-kubernetes-k8s-af4e68f7c358